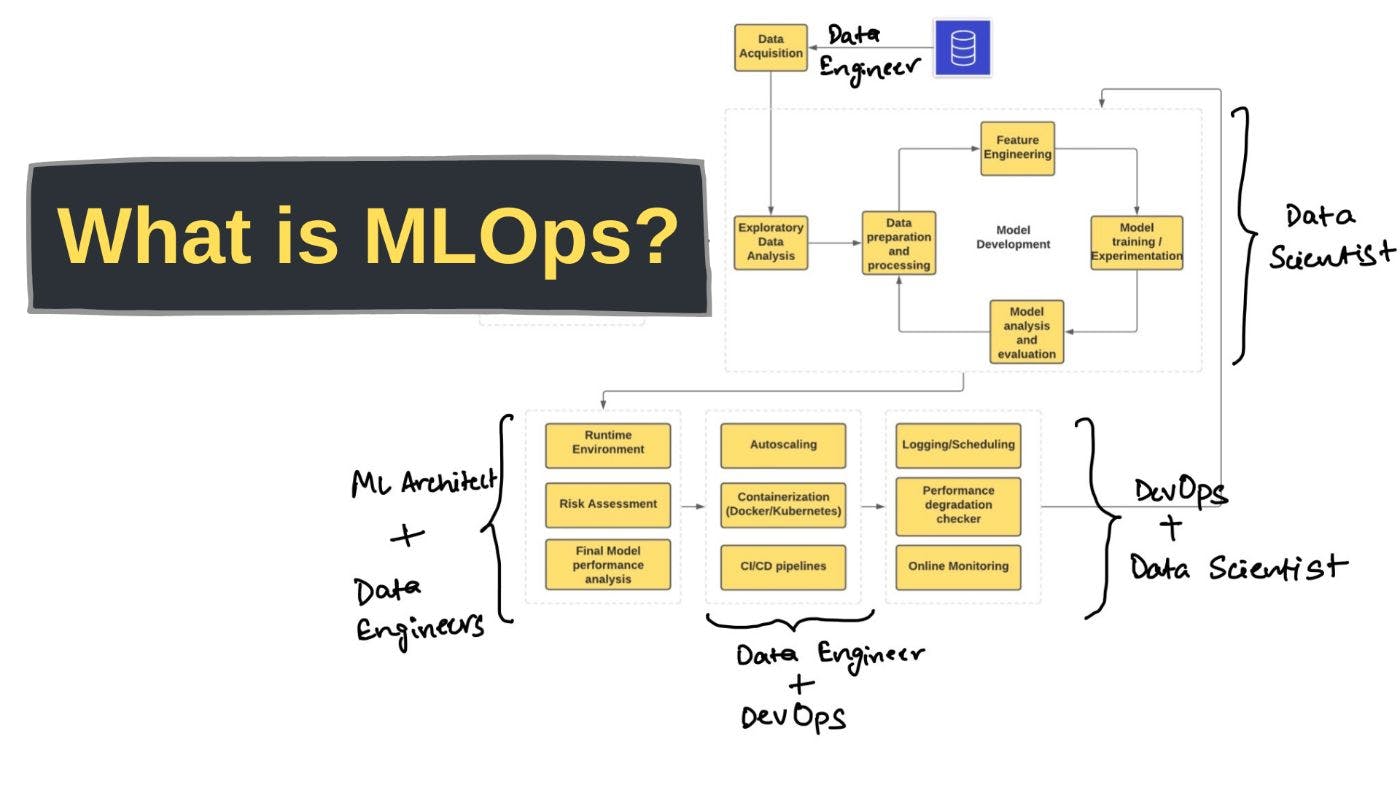
Hi Hackernoon! In this article, I will discuss the concept of MLOps in detail. Moreover, I will do it in 3 ways. First, theoretically - through the most sensible MLOps scheme. Then, conceptually, through the artifacts that are embedded in the approach. And finally, through understanding MLOps as an information system.
So, let’s start.
What is MLOps?
MLOps Abstract Decomposition


This question has long occupied the minds of many ML systems development teams. By such a system in this article, I will understand an information system, one or more components of which contain a trained model that performs some part of the overall business logic.
Like any other component of the system, this part of the business logic needs to be updated to meet changing business and customer expectations. MLOps is all about this regular update.
MLOps definition and explanation
There has yet to be a single and agreed definition of MLOps. Many authors have tried to give it, but it was challenging to find a clear and systematic description at the same time.
There is one that could be considered such:
MLOps is an engineering discipline that aims to unify ML systems development(dev) and ML systems deployment(ops) to standardize and streamline the continuous delivery of high-performing models in production.
Let's highlight the critical parts of the MLOps definition:
- Engineering discipline
- Aims to unify the development and deployment processes of ML systems
- Standardizes and optimizes the continuous delivery of new versions
- High-performance models
So, MLOps is a kind of DevOps for ML models.
History of the MLOps emergence
It is easy to believe that such an engineering discipline originated in a large IT company. So we can trust the theory that MLOps, as a meaningful approach, originated at Google, where D. Sculley was trying to save his nerves and time from the mundane tasks around outputting ML models to extensions. D. Sculley is now widely known as "The Godfather of MLOps" - the podcast of the same name is easy to find online.
D. Sculley began to consider the work with models from the point of view of the team's technical debt. Yes, it is possible to release new versions of models quickly, but the cost of supporting the resulting system will have a significant impact on the company's budget.
His work resulted in the paper "
MLOps maturity levels: the best-known models
Like most IT processes, MLOps have maturity levels. They help companies understand where they are now and how they can move to the next level (if there is such a goal). Also, generally accepted maturity determination methods allow you to determine your place among competitors.
GigaOm MLOps maturity model
The most thoroughly described and largely understandable model is from the analytics firm GigaOm. It is closest to the Capability Maturity Model Integration (CMMI) of all the models. This is a set of methodologies for improving organizational processes, which also consists of 5 levels - from 0 to 4.
An MLOps Maturity Model By GigaOm

The model from GigaOm unpacks each maturity level through 5 categories: strategy, architecture, modeling, processes, and governance.
Guided by this model in the early stages of building an ML system, you can think ahead about essential aspects and reduce the chances of failure. Moving from one maturity level to a higher one presents the team with new challenges that they may not have realized existed before.
Google MLOps maturity model
It's worth noting that Google also has its MLOps maturity levels model. It was one of the first to appear. It is concise and consists of 3 levels:
- Level 0: Manual process
- Level 1: ML pipeline automation
- Level 2: CI/CD pipeline automation
It's hard to escape the thought that this model resembles an instruction manual for painting an owl. First, do everything by hand, assemble the ML pipelines, and finalize the MLOps. That said, it is well described.
Azure MLOps maturity model
Today, many large companies using ML have compiled their maturity models.
- Level 0: No MLOps
- Level 1: DevOps but no MLOps
- Level 2: Automated Training
- Level 3: Automated Model Deployment
- Level 4: Full MLOps Automated Operations
All the highlighted models converge in approximately one thing. At the zero level, they have the absence of any ML practices. At the last level, they have the automation of MLOps processes. There's always something different in the middle that is related to incremental process automation. Azure has this automation of the training process and then model deployment.
MLOps Conceptual Framework
How do you describe all the processes associated with the concept of MLOps? Surprisingly, three Germans - the authors of the article "
End-to-end MLOps architecture and workflow with functional components and roles
It can be intimidating as it has many elements interacting with each other. However, many of the characteristics of the maturity levels mentioned above can be found in it. At least automated Pipelines, CI/CD, Monitoring, Model Registry, Workflow Orchestration, and Serving Component.
Let's discuss this diagram and talk about each one in more detail.
MLOps Core Processes
The main parts of the scheme are horizontal blocks, within which the procedural aspects of MLOps are described (they are assigned letters A, B, C, and D). Each of them is designed to solve specific tasks within the framework of ensuring the smooth operation of ML services of the company. For ease of understanding the scheme, it is better to start out of order.
Experimentation
If a company has ML services, employees work in Jupyter. In many companies, this is the tool where all ML development processes are centered. This is where most of the tasks that require implementing MLOps practices start.
Let's consider an example. Company A needs to automate a part of some processes using machine learning (let's assume that there is a corresponding department and specialists). It is unlikely that the way to solve the task is known in advance. Therefore, the executors need to study the problem statement and test possible ways of its realization.
To do this, an ML engineer/ML developer writes code for various task implementations and evaluates the results obtained by target metrics. All this is almost always done in Jupyter Lab. In such a form, it is necessary to capture a lot of important information manually and then compare implementations among themselves.
Such activity is called experimentation. It means obtaining a working ML model, which can be further used to solve relevant problems.
Block C shown in the diagram describes the process of conducting ML experiments.
ML Experimentation Zone in end-to-end MLOps architecture

Analyzing the data available within the scope of the task
Many decisions in ML development are made based on analyzing the data available in the company. It is not possible to train a model with target quality metrics on low-quality data or data that does not exist.
Therefore, it is important to figure out what data we have gotten and what we can do with it. To do this, for example, we can:
- Conduct an ADHoc study using Jupyter or Superset
- Standard EDA (Exploratory Data Analysis)
A better understanding of the data can only be obtained when coupled with semantic and structural analysis.
Only sometimes, however, data preparation is within the project team's control. In this case, additional difficulties are assured. Sometimes at this stage, it becomes clear that there is no point in developing the project further because the data is not suitable for work.
Formation of a quality dataset
When there is confidence in the available data, it is necessary to think about the preprocessing rules. Even if there is a large set of suitable data, there is no guarantee that it does not contain omissions, distorted values, etc. The term "input data quality" and the well-known phrase "Garbage in - garbage out" should be mentioned here.
No matter how good a model is used, it will produce poor results on low-quality data. In practice, many project resources are spent on creating a high-quality dataset.
ML model training and validation
After the previous stage, it makes sense to consider the metrics of the trained model when conducting experiments. Within the framework of the block under consideration, the experiment consists of linking training and validation of the ML model.
The experiment consists of the classical scheme of training the desired version of the model with the selected set of hyperparameters on the prepared dataset. For this purpose, the dataset itself is divided into training, test, and validation samples:
- The first two are used to select the optimal set of hyperparameters
- The third one is the final verification and confirmation that the model trained on the selected set of hyperparameters behaves adequately on unknown data that did not participate in the process of hyperparameter selection and training
You can read more about validation samples in
Saving code and hyperparameters in a repository
If the model learning metrics are good, the model code and the selected parameters are stored in a corporate repository.
The fundamental goal of the experimentation process is model engineering, which implies the selection of the best algorithm selection and the selection of the best hyperparameter tuning.
The difficulty of conducting experiments is that the developer needs to check many combinations of ML-model operation parameters. And we are not talking about different variants of the used mathematical apparatus.
In general, it takes work. And what to do if the desired metrics are not achieved within the framework of combinations of model parameters?
Feature engineering
If the desired metrics of ML-model operation cannot be achieved, you can try to extend the feature description of dataset objects with new features. Due to them, the context for the model will expand, and therefore, the desired metrics may improve.
New features may include:
- For tabular data: arbitrary transformations of already existing object attributes - e.g., X^2, SQRT(X), Log(x), X1*X2, etc.
- Based on the subject area: body mass index, number of overdue loan payments for a year, etc.
Data Engineering Zone in end-to-end MLOps architecture

Let's look at the part of the diagram that relates to Feature Engineering.
Block B1 aims to form a set of requirements for transforming the available source data and obtaining features from them. The calculation of the components itself is performed from these very preprocessed and cleaned data according to the "formulas" entered by the ML developer.
It is essential to say that working with features is iterative. Applying one set of features, a new idea may come to mind, realized in another set of features, and so on, ad infinitum. This is explicitly shown in the diagram as a Feedback Loop.
Block B2 describes the immediate process of adding new features to the data.
Connecting to and retrieving data sources are technical operations that can be pretty complicated. For simplicity of explanation, I will assume that there are several sources to which the team has access and tools to unload data from these sources (at least Python scripts).
Data cleaning and transformation. This stage almost hoes the similar step in the block of experiments (C) - data preparation. Already at the set of the first experiments, there is an understanding of what data and in what format are needed for training ML models. All that remains is to generate and test new features correctly, but the data preparation process for this purpose should be automated as much as possible.
Computation of new features. As noted above, these actions can consist of simply transforming a few elements of a data tuple. Another option is to run a separate large processing pipeline to add a single feature to the same data tuple. Either way, there is a set of actions that are sequentially executed.
Adding the result. The result of the previous actions is added to the dataset. Most often, features are added to the dataset in batch to reduce the database load. But sometimes it is necessary to do it on the fly (streaming) to speed up the execution of business tasks.
It is essential to use the obtained features as efficiently as possible: save and reuse them in tasks of other ML developers of the company. The scheme has a Feature store for this purpose. It should be available inside the company, separately administered, and versioned all the features that get into it. The Feature store has 2 parts: online (for streaming scripts) and offline (for batch scripts).
Automated ML Workflow
At the beginning of the article, I indicated that by ML system I mean an information system, one or more components of which contain a trained model that performs some part of the overall business logic. The better the ML model obtained due to development, the greater the effect of its operation. A trained model processes the incoming stream of requests and provides some predictions in response, thus automating some parts of the analysis or decision-making process.
The process of using a model to generate predictions is called inference, and training a model is called training. A clear explanation of the difference between the 2 can be borrowed from Gartner. Here, I will practice on cats.
Difference Between Training And Inference Data Inputs to ML Models

For the efficient operation of a production ML system, it is vital to keep an eye on the inference metrics of the model. As soon as they start dropping, the model should be either retrained or replaced with a new one. Most often, it happens due to changes in input data (data drift). For example, there is a business problem in which the model can recognize cupcakes in photos, and it is given this as input. The Chihuahua dogs in the example are for balance:
Example of CAPTCHA with cupcakes and Chihuahua dogs

The model in the original dataset does not know anything about the Chihuahua dogs, so it predicts incorrectly. So, it is necessary to change the dataset and conduct new experiments. The new model should be in production as soon as possible. No one forbids users to upload Chihuahua dog images, but they will get the wrong results.
Now to more real-world examples. Let's consider the development of a recommendation system for a marketplace.
Based on the user's purchase history, purchases of similar users, and other parameters, a model or ensemble of models generates a block with recommendations. It contains products whose purchase revenue is regularly counted and tracked.
Something happens, and customers' needs change. Consequently, their recommendations are no longer relevant. Demand for the recommended products drops. All this leads to a decrease in revenue.
Next managers scream and demand everything to be restored by tomorrow, which leads to nothing. Why? There is insufficient data on new customer preferences, so you can't even make a new model. You can take some basic algorithms of recommendation generation (item-based collaborative filtering) and add them to production. In this way, recommendations will somehow work, but this is only a temporary workaround.
Ideally, the process should be set up in such a way that the process of retraining or experimenting with different models is started based on metrics without managers telling them to do so. And the best one would eventually replace the current one in production. In the diagram, this is the Automated ML Workflow Pipeline (block D), which is started by triggers in some orchestration tool.
ML Production Zone in end-to-end MLOps architecture

This is the most heavily loaded section of the scheme. Several key third-party components are involved in the operation of block D:
- The workflow orchestrator component, which is responsible for launching the pipeline on a specified schedule or event
- Feature Store, from which data on necessary features for the model is taken
- Model Registry and ML metadata store, where the models and their metrics, obtained after the work of the launched Pipeline, are placed
The structure of the block itself combines the stages of the experimentation and feature development (B2) blocks. It's not surprising, considering that these are the processes that need to be automated. The main differences are in the last 2 stages:
- Export model
- Push to the model registry
The remaining steps are identical to those described above.
Separately, I want to mention service artifacts that are required by the orchestrator to run model retraining pipelines. This is the code that is stored in the repository and runs on selected servers. It is versioned and upgraded following all the rules of software development. This code implements the model retraining pipelines, and the result depends on its correctness.
More often than not, various ML tools are run within the code, within which the execution of the steps of the pipelines takes place, for example:
- The airflow orchestrator runs the code to execute the stages of the pipelines
- Feast unloads data about the features in the dataset on command
- Then ClearML creates a new dataset and runs an experiment with the necessary set of model performance metrics, which it takes from its own repository
- After the investigation is completed, ClearML saves the model and its performance metrics to the storage
It is worth noting here that it is generally impossible to automate experiments. It is possible, of course, to add the AutoML concept to the process. However, there is currently no recognized solution that can be used with the same results for any subject of the experiment.
In the general case, AutoML works like this:
- Somehow generates a set of many combinations of model operation parameters
- Runs an experiment for each resulting combination. Fixes metrics for each experiment based on which the best model is selected
- AutoML does all the manipulations that a Junior/Middle Data Scientist would do in a circle of more or less standard tasks
Automation has been dealt with a bit. Next, we need to organize the delivery of a new version of the model to production.
Serving and monitoring models
ML model is required to generate predictions. But the ML model itself is a file, which cannot be made to generate them so quickly. You can often find such a solution on the Internet: a team takes FastAPI and writes a Python wrapper around the model so that you can “follow the predicates”.
From the moment the ML model file is received, there are several ways things can unfold. The team can go:
- Write all the code to build a RESTfull service
- Implement all the wrapping around it
- Build it all into a Docker image
- And then somewhere from that image, you're going to build a container
- Scale it somehow
- Organize the collection of metrics
- Set up alerting
- Set up rules for rolling out new versions of the model
- A lot of other things
It is a labor-intensive task to do this for all models and to maintain the entire code base in the future. To make it easier, special serving tools have appeared, which introduced 3 new entities:
- Inference Instance/Service
- Inference Server
- Serving Engine
An Inference Instance, or Inference Service, is a specific ML model prepared to receive queries and generate response predictions. Such an entity can represent a sub in a Kubernetes cluster with a container with the necessary ML model and the technical tooling to run it.
The Inference Server is the creator of Inference Instances/Services. There are many implementations of Inference Server. Each can work with specific ML frameworks, converting the models trained in them into ready-to-use models for processing input queries and generating predictions.
The Serving Engine performs the primary management functions. It determines which Inference Server will be used, how many copies of the resulting Inference Instance should be started, and how to scale them.
In the scheme under consideration, there is no such detailing of model serving components, but similar aspects are outlined:
- CI/CD component, which deploys models ready to run in production (it can be considered as one of the versions of Serving Engine)
- Model Serving, within the infrastructure available to it, organizes the scheme of prediction generation for ML models, both for streaming and batch scenarios (it can be considered as one of the versions of Inference Server)
CI/CD Component in ML Production Zone

For an example of a complete stack for Serving, we can refer to the stack from Seldon:
- Seldon Core is the Serving Engine
- Seldon ML Server is the Inference Server, which prepares access to the model via REST or gRPC
- Seldon MLServer Custom Runtime is the Inference Instance, a shell instance for any ML model whose example needs to be run to generate predictions.
There is even a standardized protocol for implementing Serving, support for which is de facto mandatory in all such tools. It is called V2 Inference Protocol and has been developed by several prominent market players - KServe, Seldon, and Nvidia Triton.
Serving vs. Deploying
In various articles, you may find references to the tools for Serving and Deploying as a single entity. However, it is essential to understand the difference in the purpose of both. This is a debatable issue, but this article will put it this way:
- Serving - the creation of an API model and the possibility to get predictions from it. In the end, you get a single service instance with a model inside.
- Deploy - distributing the service instance in the necessary quantity to process incoming requests (can be represented as a replica set in Kubernetes deployment).
Many strategies can be used to Deploy models, but these are not ML-specific. By the way, the paid version of Seldon supports several of the strategies, so you can just select this stack and enjoy how everything works.
Remember that model performance metrics must be tracked. Otherwise, you won't be able to solve problems in time. How exactly to track metrics is the big question. Arize AI has built a whole business on this, but nobody has canceled Grafana and VictoriaMetrics.
Project initiation
Given everything written above, it turns out that ML command:
- Generates datasets
- Conducts experiments on them on ML models
- Develops new features to extend datasets and improve the quality of models
- Saves the best models in the Model Registry for future reuse
- Customizes Serving and Deploying of models
- Customizes monitoring of models in production and automatic retraining of current models or creating new models
It looks costly and only sometimes justified. Therefore, there is a separate MLOps Project Initiation (A) block in the diagram responsible for rational goal setting.
MLOps Project Initiation Zone in end-to-end MLOps architecture

An example of the IT director's reasoning can demonstrate the way of thinking here. An inspired project manager comes to him and asks for a new platform installation for building an ML system. If both are acting in the best interest of the company, clarifying questions will follow from the IT director:
- What business problem are you going to solve with the new ML system?
- Why did you decide that the new ML system should solve this problem?
- Would it be easier and cheaper to change processes or hire more people in technical support?
- Where can you see a comparative analysis of the ML-system components that formed the basis for your current selection?
- How will the chosen ML-system architecture help solve a business problem?
- Are you sure that ML has the necessary mathematical apparatus to solve the identified problem?
- What is the problem statement for the solution?
- Where will you get the data to train the models? Do you know what data you need to prepare the models?
- Have you already examined the available data?
- Is the quality of the data sufficient to solve the model?
The IT director will be brought down as a teacher in a university but will save the company's money. If all the questions have been answered, there is a real need for an ML system.
Next question: Do I need to do MLOps in it?
Depends on the problem. If you need to find a one-time solution, for example, PoC (Proof of Concept), you don't need MLOps. If it is essential to process many incoming requests, then MLOps is required. In essence, the approach is similar to optimizing any corporate process.
To justify the need for MLOps to management, you need to prepare answers to the questions:
- What is going to get better?
- How much money we'll save?
- Whether we need to expand our staff?
- What do we need to buy?
- Where to gain expertise?
The next thing to do is to retake the IT director's exam.
The challenges continue because the team must also be convinced of the need to change their work processes and technology stack. Sometimes, this is more difficult than asking management for a budget.
To convince the team, it is worth preparing answers to the questions:
- Why the old way of working is no longer possible?
- What is the purpose of the change?
- What the technology stack will be?
- What and from whom to learn?
- How the company will assist in implementing the changes?
- How long does it take to make the change?
- What happens to those who don't make it?
As you can see, this process isn’t simple.
Small conclusion
I'm done here with a detailed study of the MLOps scheme. However, these are only theoretical aspects. Practical implementation always reveals additional details that can change a lot of things.
In the next article, I will discuss:
- MLOps artifacts
- MLOps as an information system
- Open Source for MLOps: Kubeflow vs. MLflow vs. Pachyderm
Thank you for your attention!