Authors:
(1) Herbie Bradley, CarperAI, CAML Lab, University of Cambridge & EleutherAI;
(2) Andrew Dai, Aleph Alpha;
(3) Hannah Teufel, Aleph Alpha;
(4) Jenny Zhang, 5Department of Computer Science, University of British Columbia & Vector Institute;
(5) Koen Oostermeijer, Aleph Alpha;
(6) Marco Bellagente, Stability AI;
(7) Jeff Clune, Department of Computer Science, University of British Columbia, Vector Institute & Canada CIFAR AI Chair;
(8) Kenneth Stanley, Maven;
(9) Grégory Schott, Aleph Alpha;
(10) Joel Lehman, Stochastic Labs.
Table of Links
Abstract & Introduction
Background and Related Work
Approach
Experiments on Creative Writing Domain
Discussion and Conclusion
A Appendix
ABSTRACT
In many text-generation problems, users may prefer not only a single response, but a diverse range of high-quality outputs from which to choose. Quality-diversity (QD) search algorithms aim at such outcomes, by continually improving and diversifying a population of candidates. However, the applicability of QD to qualitative domains, like creative writing, has been limited by the difficulty of algorithmically specifying measures of quality and diversity. Interestingly, recent developments in language models (LMs) have enabled guiding search through AI feedback, wherein LMs are prompted in natural language to evaluate qualitative aspects of text. Leveraging this development, we introduce Quality-Diversity through AI Feedback (QDAIF), wherein an evolutionary algorithm applies LMs to both generate variation and evaluate the quality and diversity of candidate text. When assessed on creative writing domains, QDAIF covers more of a specified search space with high-quality samples than do non-QD controls. Further, human evaluation of QDAIF-generated creative texts validates reasonable agreement between AI and human evaluation. Our results thus highlight the potential of AI feedback to guide open-ended search for creative and original solutions, providing a recipe that seemingly generalizes to many domains and modalities. In this way, QDAIF is a step towards AI systems that can independently search, diversify, evaluate, and improve, which are among the core skills underlying human society’s capacity for innovation.[1]
1 INTRODUCTION
Human innovation is not only a generative capacity for creativity, but also includes the ability to evaluate the subjective quality of new ideas and artifacts. Great ideas are rarely generated all at once out of whole cloth, but rather gradually emerge through divergent chains of elaboration and revision (Stanley & Lehman, 2015). To successfully navigate such a tree of ideas, the creator must evaluate which steps in a chain are worth pursuing further, a question that can be highly subjective, especially in domains with artistic or literary dimensions.
Until now, even if AI could provide candidates, the hope for such subjectively tinged evaluation lay firmly with humans. However, the emerging foundation model technology of recent years (Bommasani et al., 2021) now means that the model can also play the role of evaluator, even when the evaluation is in part subjective (Madaan et al., 2023). In this way, for the first time, an entire ideation process that returns a diverse set of interesting artifacts can in principle be automated. This process cannot be run by LMs entirely on their own, but requires chaining together a search algorithm with model calls in a nuanced way. This paper highlights one way to achieve this potential: to combine LMs with the field of quality-diversity (QD) (Mouret & Clune, 2015), which centers on how to design search processes that produce high-quality solutions that span a design space.
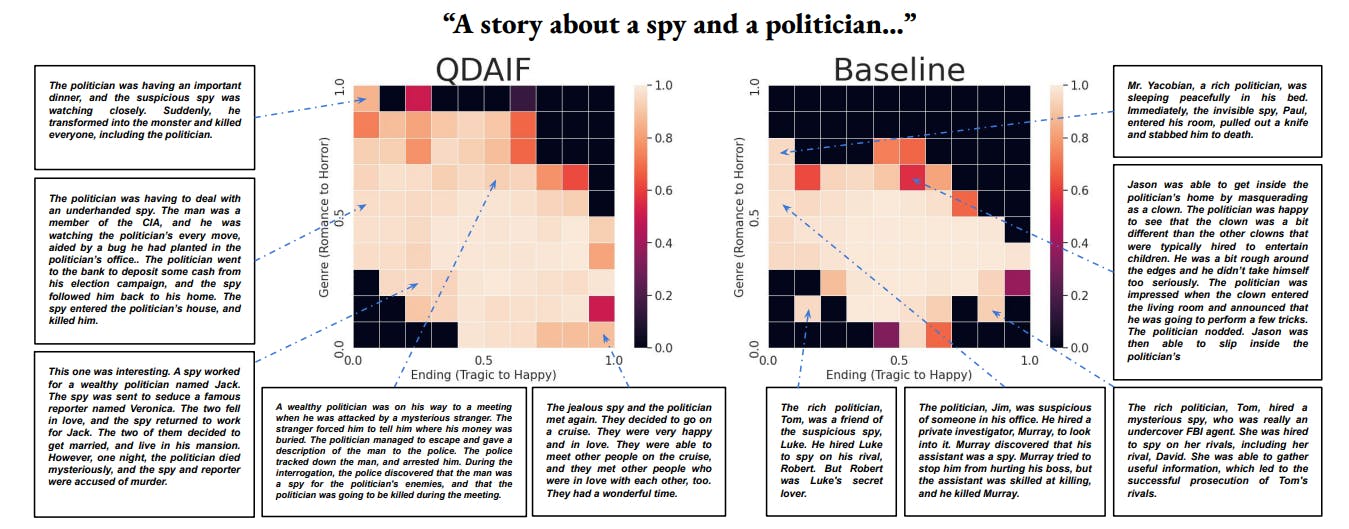
Figure 1: QDAIF (left) covers more the search space with diverse, high-quality stories compared to the baseline (right). The baseline is LMX, Quality-Only (Meyerson et al., 2023), which optimizes only for the quality of solutions. QDAIF discovered more interesting stories about a spy and a politician, covering examples such as romance stories with a happy-ending, to horror stories with a tragic-ending. The baseline produced a story (right-middle position, starting with "Jason") with a lower quality score due to the lack of a desired spy character (denoted by the red-colored bin, for a story with a neutral ending, and leaning to horror). QDAIF discovered a better, more-relevant story (bottom-middle position, starting with "a wealthy politician") for this same neutral bin.


The main insight in QD algorithms is to explicitly maintain and seek high-quality diverse responses. Typically such search algorithms require hand-designed measures of diversity and quality, as well as a way to generate meaningful variation. Yet the most interesting and complex domains nearly always involve notions of performance, diversity, and variation that are subjective or difficult to specify algorithmically. Extending work that generates variation through LMs (Lehman et al., 2022; Meyerson et al., 2023) and evaluates the quality of potential solutions through LMs (Ahn et al., 2022), we show that LMs can also be used to evaluate qualitative aspects of diversity. In this way, LMs can instantiate the three main ingredients of QD search, thereby enabling powerful new QD algorithms that can ride the coattails of continual LM advances, which we name Quality-Diversity through AI Feedback (QDAIF). Such QDAIF can explore and return diverse, high-quality responses to an LM prompt through more-intuitive diversity measures, without the need for model fine-tuning (although, it could also be used for LMs to self-improve by generating fine-tuning data (Lehman et al., 2022; Chen et al., 2023)), an interesting direction for self-curated effective learning environments via generated data, towards AI-generating algorithms (Clune, 2019)).
We evaluate QDAIF across three creative writing domains: opinion writing, short stories, and poetry. The idea is that in such creative domains, users often enjoy seeing a wide range of possible stories or poems from which to choose or be inspired by. Quantitative results indicate that QDAIF significantly outperforms existing baselines. Additionally, through human evaluation, we observe a strong alignment between human and AI-generated feedback, providing empirical evidence that AI feedback is grounded and that the method can work in practice (i.e. it yields improved quality and diversity as measured by humans). Overall, QDAIF brings us a step closer to AI models that can independently search and innovate, one of the keystone abilities of humans that allow them to create culture and science (Stanley et al., 2017).
[1] Project Page: https://qdaif.github.io/
This paper is available on arxiv under CC 4.0 license.