Authors:
(1) Savvas Petridis, Google Research, New York, New York, USA;
(2) Ben Wedin, Google Research, Cambridge, Massachusetts, USA;
(3) James Wexler, Google Research, Cambridge, Massachusetts, USA;
(4) Aaron Donsbach, Google Research, Seattle, Washington, USA;
(5) Mahima Pushkarna, Google Research, Cambridge, Massachusetts, USA;
(6) Nitesh Goyal, Google Research, New York, New York, USA;
(7) Carrie J. Cai, Google Research, Mountain View, California, USA;
(8) Michael Terry, Google Research, Cambridge, Massachusetts, USA.
Table Of Links
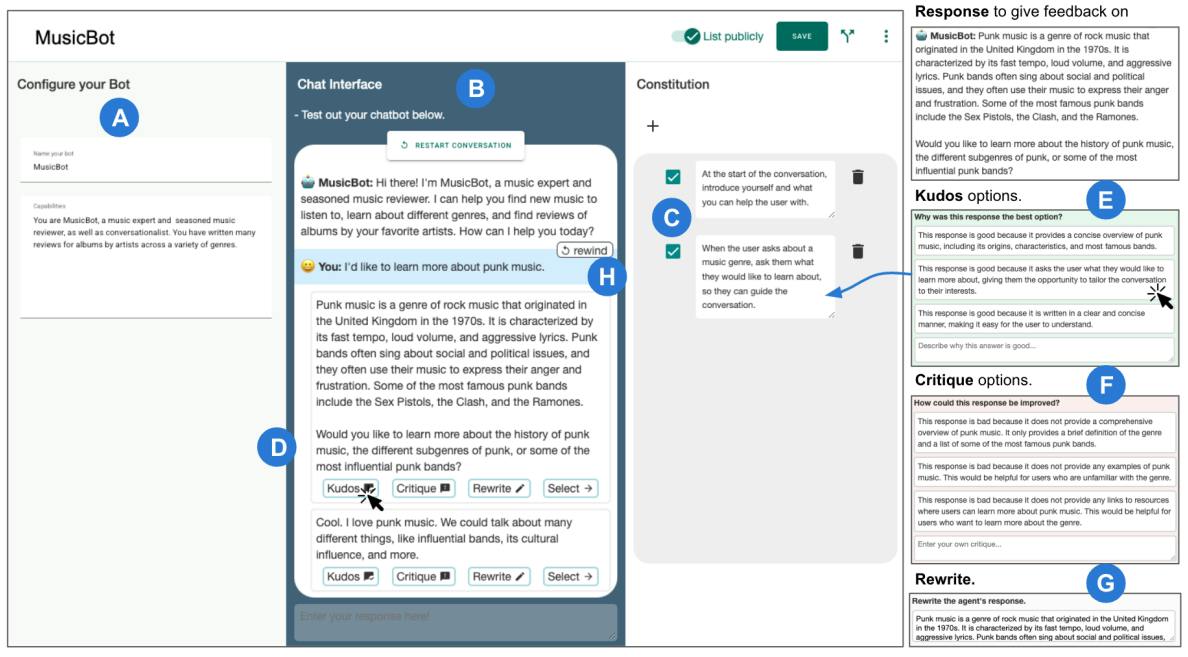
Figure 1: ConstitutionMaker’s Interface. First, users name and describe the chatbot they’d like to create (A). ConstitutionMaker constructs a dialogue prompt, and users can then immediately start a conversation with this chatbot (B). At each conversational turn, users are presented three candidate responses by the chatbot, and for each one, three ways to provide feedback: (1) kudos, (2) critique, and (3) rewrite. Each feedback method elicits a principle, which gets added to the Constitution in (C). Principles are rules that get appended to the dialogue prompt. Giving kudos to an output (D) entails providing positive feedback, either through selecting one of three generated positive rationales or by writing custom positive feedback. Critiquing (F) is the same but providing negative feedback. And finally, rewriting (G) entails revising the response to generate a principle.


ABSTRACT
Large language model (LLM) prompting is a promising new approach for users to create and customize their own chatbots. However, current methods for steering a chatbot’s outputs, such as prompt engineering and fine-tuning, do not support users in converting their natural feedback on the model’s outputs to changes in the prompt or model. In this work, we explore how to enable users to interactively refine model outputs through their feedback, by helping them convert their feedback into a set of principles (i.e. a constitution) that dictate the model’s behavior. From a formative study, we (1) found that users needed support converting their feedback into principles for the chatbot and (2) classified the different principle types desired by users. Inspired by these findings, we developed ConstitutionMaker, an interactive tool for converting user feedback into principles, to steer LLM-based chatbots. With ConstitutionMaker, users can provide either positive or negative feedback in natural language, select auto-generated feedback, or rewrite the chatbot’s response; each mode of feedback automatically generates a principle that is inserted into the chatbot’s prompt. In a user study with 14 participants, we compare ConstitutionMaker to an ablated version, where users write their own principles. With ConstitutionMaker, participants felt that their principles could better guide the chatbot, that they could more easily convert their feedback into principles, and that they could write principles more efficiently, with less mental demand. ConstitutionMaker helped users identify ways to improve the chatbot, formulate their intuitive responses to the model into feedback, and convert this feedback into specific and clear principles. Together, these findings inform future tools that support the interactive critiquing of LLM outputs.
CCS CONCEPTS
• Human-centered computing → Empirical studies in HCI; Interactive systems and tools; • Computing methodologies → Machine learning.
KEYWORDS
Large Language Models, Conversational AI, Interactive Critique
1 INTRODUCTION
Large language models (LLMs) can be applied to a wide range of problems, ranging from creative writing assistance [8, 26, 36, 44] to code synthesis [13, 14, 20]. Users currently customize these models to specific tasks through strategies such as prompt engineering [4], parameter-efficient tuning [19], and fine-tuning [10].
In addition to these common methods for customizing LLMs, recent work has shown that users would also like to directly steer these models with natural language feedback (Figure 2A). More specifically, some users want to be able to critique the model’s outputs to specify how they should be different [5]. We call this customization strategy interactive critique.
When interacting with a chatbot like ChatGPT[1] [28] or Bard[2], interactive critique will often alter the chatbot’s subsequent responses to conform to the critique. However, these changes are not persistent: users must repeat these instructions during each new interaction with the model. Users must also be aware that they can actually alter the model’s behavior in this way, and must formulate their critique in a way that is likely to lead to changes in the model’s future responses. Given the potential value of this mode of customizing there is an opportunity to provide first-class support for empowering users to customize LLMs via natural language critique.
In the context of model customization, Constitutional AI [1] offers a specific customization strategy involving natural language principles. A principle can be thought of as a rule that the language model should follow, such as, “Do not create harmful, sexist, or racist content”. Given a set of principles, a Constitutional AI system will 1) rewrite model responses that violate principles and 2) fine-tune the model with the rewritten responses. Returning to the notion of interactive critique, one can imagine deriving new or refined Constitutional AI principles from users’ critiques. These derived principles could then be used to alter an LLM’s prompt (Figure 2B) or to generate new training data, as in the original Constitutional AI work.
While this recent work has shown principles can be an explainable and effective strategy to customize an LLM, little is known about the human processes of writing these principles from our feedback. From a formative study, we discovered that there are many cognitive challenges involved in converting critiques into principles. To address these challenges, we present ConstitutionMaker, an interactive critique system that transforms users’ model critiques into principles that refine the model’s behavior. ConstitutionMaker generates three candidate responses at each conversational turn. In addition to these three candidate responses, ConstitutionMaker provides three principle-elicitation features: 1) kudos, where users can provide positive feedback for a response, 2) critique, where users can provide negative feedback for a response, and 3) rewrite, where users can rewrite a given response. From this feedback, ConstitutionMaker infers a principle, which is incorporated in the chatbot’s prompt.
To evaluate how well ConstitutionMaker helps users write principles, we conducted a within-subjects user study with 14 industry professionals familiar with prompting. Participants used ConstitutionMaker and an ablated version that lacked the multiple candidate responses and the principle-elicitation features. In both cases, their goal was to write principles to customize two chatbots. From the study, we found that the two different versions yielded very different workflows. With the ablated version, participants only wrote principles when the bot deviated quite a bit from their expectations, resulting in significantly fewer principles being written, in total. In contrast, in the ConstitutionMaker condition, participants engaged in a workflow where they scanned the multiple candidate responses and gave kudos to their favorite response, leading to more principles overall. These different workflows also yielded condition-specific challenges in writing principles. With the ablated version, users would often under-specify principles; whereas, with ConstitutionMaker, users sometimes overspecified their principles, though this occurred less often. Finally, both conditions would sometimes lead to an issue where two or more of the principles were in conflict with one another.
Figure 2: Illustration of steering an LLM via interactive critique. In conversations with LLMs like Chat-GPT and Bard, usersprovide natural language feedback, as they would to another person, to steer the LLM to better outputs. In this example, the

Overall, with ConstitutionMaker, participants felt that their principles could better guide the chatbot, that they could more easily convert their feedback into principles, and that they could write principles more efficiently, with less mental demand. ConstitutionMaker also supported their thought processes as they wrote principles by helping participants 1) recognize ways responses could be better through the multiple candidate responses, 2) convert their intuition on why they liked or disliked a response into verbal feedback, and 3) phrase this feedback as a specific principle.
Collectively, this work makes the following contributions:
• A classification of the kinds of principles participants want to write to steer chatbot behavior.
• The design of ConstitutionMaker, an interactive tool for converting user feedback into principles to steer chatbot behavior. ConstitutionMaker introduces three novel principleelicitation features: kudos, critique, and rewrite, which each generate a principle that is inserted into the chatbot’s prompt.
• Findings from a 14-participant user study, where participants felt that ConstitutionMaker enabled them to 1) write principles that better guide the chatbot, 2) convert their feedback into principles more easily, and 3) write principles more efficiently, with less mental demand.
• We describe how ConstitutionMaker supported participants’ thought processes, including helping them identify ways to improve responses, convert their intuition into natural language feedback, and phrase their feedback as specific principles. We also describe how the different workflows enabled by the two systems led to different challenges in writing principles and the limits of principles.
Together, these findings inform future tools for interactively refining LLM outputs via interactive critique.
[1] https://chat.openai.com/
[2] https://bard.google.com
This paper is available on arxiv under CC 4.0 license.