
Looks like it’s part 2 of my series on Data Quality!
In a previous post, I explored Airbnb’s strategy for enhancing data quality through incentives. They implemented a single score and clear scoring criteria to establish a common understanding between data producers and consumers, fostering a genuine sense of ownership.

Data Quality Score: One Score to Rule Them All | HackerNoon
One score to rule them all, one score to find them, one score to bring them all and in the data's clarity bind them.
Now, Lyft is taking a distinct approach, not attempting the same thing differently, but rather focusing on different aspects of data quality. And, Lyft’s strategy complements Airbnb’s efforts. While I regard Airbnb’s DQ score (or any similar score) as an effective means to consolidate various attempts at elevating data quality, Lyft is tackling this challenge from a different angle.
The Airbnb’s DQ score serves as a valuable tool for providing a concrete visualization of data quality. In essence, any initiative to enhance data quality should manifest a discernible impact on this score. On the other hand, Lyft presents one possible initiative to proactively enhance quality by testing and validating data against specific quality criteria.
From Big Data to Better Data: Ensuring Data Quality with Verity
Author: Michael McPhillips, Tech Lead at Lyft
Fundamentally, it’s a different point in the data quality lifecycle. Introducing a mechanism to improve quality necessitates the ability to measure it initially.
So, while Airbnb’s focus lies on measuring and observing data quality, relying on the producer’s interest to enhance this quality and “look good,” Lyft takes a different approach. Lyft places emphasis on actively testing and validating data quality, providing both producers and consumers with the means to effectively improve and control the quality.
Collectively, these approaches provide a comprehensive strategy to address and enhance data quality throughout its lifecycle.
For this reason, I was particularly interested in taking a closer look at Lyft’s approach.
Another factor that intrigued me is testing, more specifically, contract testing, which has been used for many years now in basic software engineering with the emergence of microservice architecture. Data contracts, however, are something more recent in the domain of data engineering and are seen as the pinnacle or one of the ultimate steps to put in place on the path to building high-quality data pipelines. This is why I wanted to examine Lyft’s approach in more detail and explore some potential parallels.
As mentioned, the approaches taken by Airbnb and Lyft are complementary and aim to achieve the same goal: improving data quality.
Airbnb has developed the DQ score, which focuses on measuring and enhancing 4 distinct aspects of data quality:
DQ Score has guiding principles, including full coverage, automation, actionability, multi-dimensionality, and evolvability. It has dimensions like Accuracy, Reliability, Stewardship, and Usability.
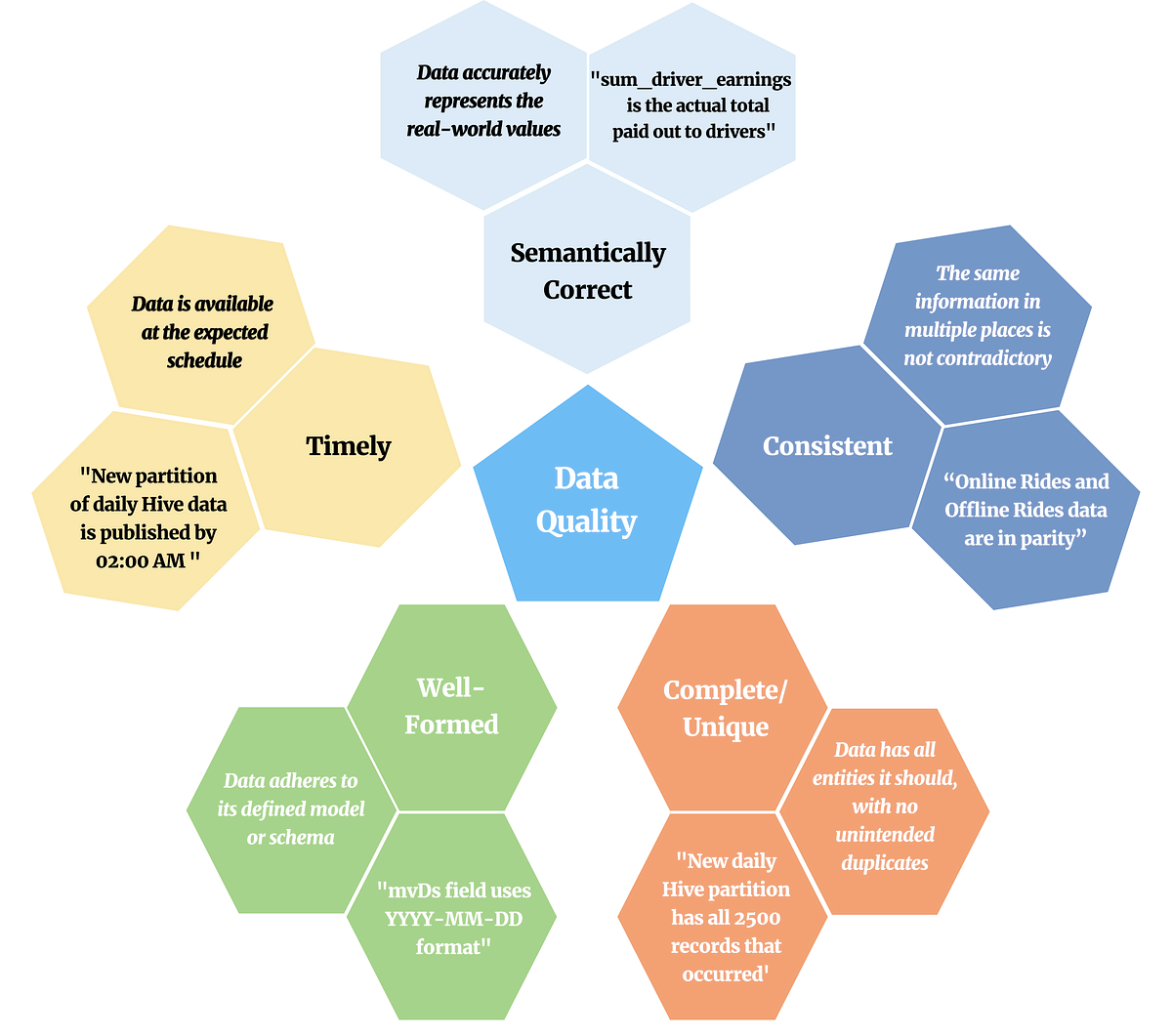
Lyft’s Verity is a platform designed to enhance data quality across 5 dimensions
Defines data quality as the measure of how well data can be used as intended, covering aspects like semantic correctness, consistency, completeness, uniqueness, well-formedness, and timeliness.
Five aspects of data quality with the definition in italics and an example in quotes. (extracted from the original Lyft’s article)


It’s easy to draw parallels between the 5 data quality aspects improved by Lyft’s Verity and the 4 data quality dimensions measured by the Airbnb’s DQ score. For example, aspects like Timeliness would certainly contribute to the DQ score’s Reliability, while Accuracy would be dependent on semantic correctness, completeness, and uniqueness of the data. The Usability score, on the other hand, is influenced by the consistency of the data among other factors.
High-level User Story of a Verity customer (extracted from the original Lyft’s article)

Lyft’s Verity focuses on defining checks related to semantic correctness, consistency, completeness, uniqueness, well-formedness, and timeliness. It follows a test-first and validation approach, whereas Airbnb’s unified DQ score emphasizes evaluating data quality through various dimensions.
If we wanted to incorporate the DQ score into this last schema, it would be on the side of the Alert/Debug steps.
Airbnb’s DQ score uses different signals to assess data quality across the Accuracy, Reliability, Stewardship, and Usability aspects.
We also had a set of input signals that more directly measure quality (Midas certification, data validation, bugs, SLAs, automated DQ checks, etc.), whereas others were more like proxies for quality (e.g., valid ownership, good governance hygiene, the use of paved path tooling).
As discussed earlier, there are likely overlaps between Airbnb’s DQ score and Verity. While Airbnb focuses on pushing data quality to the right, emphasizing measurement and scoring, Lyft’s Verity takes a proactive approach by shifting the check definition configurations, testing, and validation processes to the left, emphasizing proactive improvement of data quality.
Now, my primary interest lies to the left, in the check definition configurations, testing, and validation aspects.
How Lyft integrates data quality testing into its processes?
Let’s first examine the execution paths.
Currently, Lyft’s Verity is primarily focused on ensuring the quality of data stored in its Hive data warehouse. However, there are plans to expand its capabilities to support other data sources in the future.
Note that while they refer to Hive as a data workhouse, they actually utilize it as a hybrid data storage solution, operating as a data warehouse for structured, processed, and cleansed data (silver layer) while also serving as a data lake for raw event data (bronze layer).
Poor data quality in Hive caused tainted experimentation metrics, inaccurate machine learning features, and flawed executive dashboards.
Simplified view of the Analytic Event Lifecycle in Lyft’s Data Platform (extracted from the original Lyft’s article)

Verity’s checks can be integrated into an Airflow DAG to ensure that only high-quality raw data is processed and stored in Hive as derived data.
Data producers and consumers can define their data quality checks and verify the data when it is produced or before it is consumed inside
Airflow orFlyte .…
The VerityAirflowOperator can be used in a blocking fashion to halt a DAG upon a check failure, preventing bad data from ever reaching production. This utilizes the “
Stage-Check-Exchange ” pattern: we create data in a staged schema, verify the data with a blocking operator, then promote it to production if it passes quality checks.
Checks can also be performed manually or scheduled automatically to verify both raw and derived data.
Verity Scheduled Checks are isolated from any data orchestration engine, so they still run even if Airflow or Flyte are completely down. This remedies a common problem of checks not alerting because the Airflow Task never ran.
So, there are essentially 3 primary ways to trigger a check: as part of an Airflow DAG, manually, or scheduled through the Verity platform/UI.
I don’t believe that current checks can be integrated into real-time streaming pipelines (such as Flink + Kafka) to validate for example data as it enters Hive (or even earlier).
Implementing this type of real-time check would enable prompt detection of discrepancies, leading to reduced storage and processing costs and overall data quality enhancement.
Well, to be thorough, Verity checks are managed through an API server, which could be used to trigger checks programmatically through some APIs.
Verity API Server — This service handles all the external APIs regarding running checks as well as persisting and retrieving their results. The API Server does not execute any checks, but rather writes a message to our Check Queue, which utilizes
SimpleQueueService (SQS).
So, maybe, you could potentially trigger these jobs in a more real-time fashion, such as from a streaming job or even, as a long stretch, by integrating with Hive change data capture (CDC).
However, when executed outside of Airflow, these jobs would not be able to block the data processing job; instead, they would generate asynchronous alerts pushed to the Check Queue. Some consumers would prefer to have data processing delayed when a check fails, while others would rather proceed and receive an alert.
Now, let’s look at these data quality tests.
Here’s an example that checks whether rider_events.session_id is never null. This is accomplished through a combination of query and condition components.
core rider events session_id is not null: # check name
metadata:
id: 90bde4fa-148b-4f06-bd5f-f15b3d2ad759
ownership_slack: #dispatch-service-dev
tags: [rides, core-data, high-priority]
query:
type: dsl
data_source_id: hive.core.rider_events
filters:
- session_id = null
condition:
type: fixed_threshold
max: 0
notifier_group:
pagerduty_policy: dispatch-service
email: dispatch-[email protected]
Verity is primarily focused on defining and enforcing data quality checks rather than defining complete data schemas.
Schema validation is not a novel concept. Several methods exist for defining event data schemas in event-based systems, such as JSON Schema, Protocol Buffers, Avro, or storage formats like Parquet. The optimal choice depends on your tech stack, usage, and specific requirements.
While data schemas are valuable for defining the overall structure of data objects or table rows, they fall short in capturing more sophisticated validation checks specific to consumers, such as data distribution, business rules, SLAs, and thresholds.
Data contracts go beyond schema validation, which focuses on identifying syntactical errors. I personally find that JSON Schema offers here a more suitable and readable option, effectively separating these structural and syntactical validation capabilities from serialization or storage concerns.
However, to address semantic errors and enhance data accuracy, having an effective means of defining data checks allows for defining the other facet of data contracts.
This is where Verity DSL comes into play.
Beyond semantical validation, data contracts offer another crucial aspect that deserves attention.
From a syntactical standpoint, validation checks remain consistent regardless of the consumer or producer involved. The set of validation rules is not tied to any specific consumer or producer and can be defined once and for all as a single schema.
However, the Verity data contract DSL offers a finer granularity defining small independent rules, which is particularly well-suited for this context: the semantic meaning and usage of the data vary depending on the specific consumer. Additionally, not all consumers need to utilize all of the properties of an object. Their expectations differ. This doesn’t imply they are contradictory (which would certainly be an issue), but rather complementary and distinct ones.
Therefore, allowing all consumers to establish unique rules that, when combined collaboratively, can provide a comprehensive understanding of the semantic significance of data quality is quite crucial.
And it’s this collaborative aspect that particularly resonates with me. Bear with me, this may seem like a stretch, but from my perspective, it’s worth mentioning. :)
Data exchange enables different teams (producers and consumers) to collaborate effectively. Establishing a shared understanding of these data exchanges is paramount, just like APIs in traditional software development. In microservice architectures, a collaborative testing approach known as consumer-driven contracts (CDC) has emerged, where consumers define the expected behavior of APIs provided by producers. Producers are responsible for verifying these contracts before releasing new versions.
I think data contracts share a similar collaborative spirit. Even though data validation is performed on real data, rather than at release time, and does not block releases, it’s based on cooperation and encourages teamwork between data producers and consumers. I strongly believe that this collaborative approach is key to improving data quality and should be further integrated into the process.
Well, I’m a big fan of drawing parallels…
Notice actually that this collaborative aspect is something mentioned also as part of Lyft’s verity charter.
The VerityUI provides a streamlined data discovery experience via the Verity Homepage. Our full-text search on the Check Definition Metadata lets users see all the checks currently being enforced and their Check Results. This has useful aggregations like owning team, table name, and tags.
I’m not entirely clear on how data contract issues are shared between consumers and producers through the Verity platform UI, but I definitely recognize the significance of collaboration through the dashboards:
- The producer of a data product interface can confidently ensure that they’re not inadvertently causing downstream breakages that they hadn’t anticipated.
- The consumer of the interface can rest assured that their reliance on the interface is not and will not be compromised.
While Verity is a remarkable tool for defining data quality checks, it’s unfortunately not open-source.
Fortunately, there’s another open-source data quality framework called Soda Core that provides similar functionality.
Soda Core is a free and open-source command-line tool and Python library that enables data engineers to test data quality. It utilizes user-defined input to generate SQL queries that run checks on datasets in a data source to find invalid, missing or unexpected data. When checks fail, they surface the data that you defined as “bad” in the check.
Soda Core: The Simplest Open Source Data Reliability Tool
Data reliability is critical for the success of organizations in today’s data-driven business environment. It is essential for making…
During a scan of a dataset, Soda Core evaluates the predefined checks to identify invalid, missing, or unexpected data.
Here’s the equivalent check using Soda.core syntax for the Verity DSL test that was previously defined.
name: rider_events_session_id_check
source: hive
query: SELECT * FROM rider_events WHERE session_id IS NULL;
raise_alert: true
threshold: 10
action: slack
message: "There are more than 10 rows that are null for the 'session_id' property in the 'rider_events' table. Please investigate this issue."
soda run --check checks/rider_events_session_id_check.yaml
Soda Core is a powerful tool for ensuring the quality of your data. It can help you to identify and fix data problems early, before they can cause issues for your business.
It’s worth noting that Soda Core can also facilitate data quality checks for streaming data by seamlessly integrating with Spark DataFrames.
While Verity’s data quality checks for Hive are applied to static datasets, the checks for streaming data need to be more lightweight and efficient.
Data would typically be processed in small batches of events, with very low latency, making them suitable for real-time checks and specific use cases like anomaly detection.
Finally, let’s mention that there are other data validation tools available, such as DeeQu, Great Expectations, …
As we wrap up, I hope you have a clearer understanding of the steps you can take to enhance your data quality journey.
We’ve seen two distinct approaches to data quality improvement, each with its own strengths and methodologies. One focuses on increasing visibility and observability, motivating data producers to raise the quality bar. The other prioritizes elevating the quality standard through a testing and validation-first approach. Both are complementary.
Verity is not merely a domain-specific language (DSL) for defining data checks; it’s a centralized platform that empowers data practitioners to collaborate effectively. This platform helps producers and consumers align on data quality expectations, including format, structure, and accuracy.
Verity’s data contract management capabilities could (is?) further enhanced by integrating with a broader set of features, such as metadata management and discovery, to address more sophisticated data quality needs.
Similar to Airbnb’s DQ score, Lyft’s Verity fosters a collaborative feedback loop between data producers and consumers. By incentivizing and empowering each team to take ownership of data quality, Verity cultivates a supportive environment where data quality continuously improves.
Found this article useful? Follow me on
Also published here.